Parlare di data-driven company in Italia è un po’ come discutere di fantascienza: molti amministratori hanno le idee poco chiare in materia e vige l’idea - errata - che una ristrutturazione del modello aziendale verso un modello più reattivo all’evolversi dei flussi di dati (big data) sia riservato solo alle grandi imprese. Per fortuna non è così. L’architettura di una data-driven company infatti offre vantaggi nell’immediato e nel lungo termine in termini di minimizzazione delle perdite e aumento del vantaggio competitivo dell’impresa. Inoltre il suo modello si basa sulla creazione di una smart data management platform, di cui si parlerà in modo approfondito più avanti, applicabile a imprese di qualsiasi dimensione.
I vantaggi di essere una data-driven company
Il primo vantaggio è sicuramente legato alla migliorata capacità decisionale. Avere sotto mano strumenti in grado di farci leggere tutti i dati dell’azienda in tempo reale e di incrociare diverse fonti per trovare l’informazione che ci serve quando ci serve offre enormi vantaggi in termini di esattezza e certezza delle decisioni prese. Un esempio concreto: una catena di negozi di abbigliamento potrebbe decidere di incrociare dati molto precisi provenienti da: dati vendite, feedback delle campagne di marketing sui social, informazioni socio-economiche sui quartieri dove si trovano i suoi negozi fisici, analisi sull’andamento della catena di distribuzione (supply chain) e persino dati meteo!
Il secondo vantaggio è una migliore “measurability”: ovvero la possibilità di misurare con esattezza e in tempi stretti il risultato di una determinata politica aziendale. Grazie al machine learning - l’apprendimento automatico delle macchine - e alla robotizzazione degli impianti è ora possibile infatti ricavare e gestire dati molto più precisi provenienti non più solo dal settore vendite ma anche dal settore produttivo. Si può così ottenere una maggiore integrazione della struttura aziendale e una più efficace organizzazione dei vari reparti con la possibilità di operare correzioni in tempo prima che sia troppo tardi.
Un terzo vantaggio infine è la possibilità di condividere gli stessi dati su tutti i livelli dell’azienda: non si è più legati a report aziendali contenenti solo le informazioni che si presume servano ad un dato reparto, ma ogni persona che ha un ruolo decisionale all’interno dell’organigramma dell’impresa ha accesso a tutti i dati e nella forma in cui li desidera, così da evitare scelte controproducenti. Dobbiamo essere sicuri che tutti i nostri collaboratori stanno “combattendo la nostra stessa guerra” e per farlo hanno tutti bisogno di avere davanti a sé il quadro generale di quello che sta accadendo.
Come è fatta l’architettura di una data-driven company
Una data-driven company si struttura principalmente su tre livelli:
- La base, ovvero il deposito dove confluiscono tutti i dati raccolti. Questo può essere gestito sia come un magazzino (dati già raggruppati in “caselle chiuse” difficilmente comunicanti tra loro) sia nella forma del così detto data lake (lago di dati, dati accumulati nella forma originale in modo che sia più facile connettere le singole informazioni tra loro e pescare immediatamente quelle che ci servono).
- Il laboratorio, ovvero il cervello di questa architettura. Qui i dati vengono analizzati, collegati, riordinati nella forma di un *Graph Database* (i dati sono messi in relazione tra loro attraverso i rapporti significativi che li legano tra loro e costituiscono una sorta di “nodi” di una grande rete) e arricchiti usando un Resource Description Framework, RDF (ovvero un modello in cui i dati raccolti vengono arricchiti con indicazioni sulle loro proprietà e sulle loro caratteristiche e su come possono collegarsi ad altri tipi di dati). Una volta questo lavoro di gestione e analisi dati era riservato ai reparti IT delle grandi aziende, ora invece ci sono strumenti intelligenti che compiono tutte le operazioni in autonomia grazie a complessi algoritmi. È il caso ad esempio di SDaaS, acronimo di Smart Data as a Service, una piattaforma che permette alle aziende di caricare i propri dati “grezzi” e ottenere in risposta un database intelligente (una “base della conoscenza” come la chiamano i data scientist) che può essere indagato a proprio piace e amplificabile con nuovi dati in qualsiasi momento sia attraverso un browser, sia tramite API. Ciò permette un grande risparmio in termini di tempo e di personale per l’azienda.
- La plancia di comando, ovvero la postazione finale da cui è possibile avere accesso ai dati raccolti e classificati e a ciò che se ne è ricavato. Le piattaforme variano molto: si va da quelle più tradizionali di analytics (dashboard, storyboard, report…) alle smart app (mobile business intelligence) fino ad arrivare a soluzioni che non richiedono nemmeno l’intervento decisionale umano, come nel caso di analisi inviate direttamente ai macchinari dell’azienda che rispondono e si adeguano grazie al machine learning.
Per tutto ciò, ne consegue che una data-driven company deve dotarsi di una strategia chiara e precisa per la gestione dei suoi dati, che inevitabilmente richiede l’implementazione di una smart data management platform la cui tipica architettura è sintetizzata dalla seguente figura (da leggersi dall’alto verso il basso in un percorso che va dai dati puri alla conoscenza di questi da parte dell’area manageriale dell’azienda)
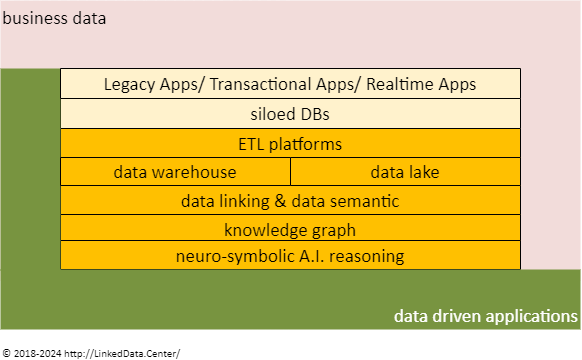
smart data management platform architecture
Per saperne di più sugli strumenti tecnologici disponibili per realizzare una smart-data platform si rimanda a questo link: